늘부터는 과제로 나온 부산의 평균최고기온 자료를 가지고
편차 그래프를 그려보고 표준편차도 구해보고 왜도와 첨도 다양한 것들을 분석해보겠습니다

자료)
자료는 기상자료 개방포털에서 가져왔습니다
1973년부터 2021년까지의 시간 규모에 부산 ASOS 관측소의 월 별 평균 최고기온 자료를 사용했습니다

이렇게 설정해 준 후 csv 형태로 다운로드 했습니다
내용)
제가 분석할 내용들은 편차, 표준편차, 각 달의 박스 플롯, IQR, 왜도, 첨도 이렇게 6가지 입니다
추가로 넣으면 좋겠다 싶은 자료들은 중간 중간 추가하겠습니다
먼저 첫 번째 포스팅에서는 편차와 표준편차를 먼저 구해보겠습니다
이번 자료는 하나의 자료를 가지고 많은 것들을 해보고 싶기 때문에 여러 개로 나눠서 하겠습니다
개념 설명)
먼저 편차란 자료의 값에서 자료의 평균을 뺀 값을 의미합니다

수식으로는 이렇게 표현할 수 있습니다
xi는 자료 값을 의미하고 x bar는 평균을 의미합니다
예를 들어 [1, 2, 3, 4, 5] 라는 자료가 있다고 하면 평균은 3이 나옵니다
그러면 xi에서 i는 자료의 갯수를 의미하기 때문에 \

1에 대한 편차와 2에 대한 편차를 이렇게 구할 수 있습니다
그러면 편차는 [-2, -1, 0, 1, 2] 이렇게 나오게 됩니다
여기서 중요한 성질은 편차의 총합은 항상 0입니다
다음은 표준편차 입니다
표준 편차를 자료가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 산포도 중에 하나 입니다
이를 수식으로 쓰면

어려워 보이지만 하나하나 해석해보면 그렇지 않습니다
먼저 xi - xbar는 편차라고 했죠?? 그럼 분자는 1부터 n까지 수들의 편차를 제곱해서 모두 더해라 라는 뜻입니다
그리고 그 값을 전체 자료 갯수로 나누고 루트를 씌우면? 표준 편차가 됩니다
표준편차를 제곱한 값, 즉 루트를 씌워 주기 전의 값을 분산이라고 합니다
오늘 파이썬으로 이 2개를 구해줄 겁니다
라이브러리)
먼저 사용한 라이브러리 들입니다
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import math
from scipy.stats import skew, kurtosiscsv 자료를 읽어오고 전처리를 위한 pandas,
그림을 그리기 위한 matplotlib, 평균과 수치 계산을 위한 numpy
수학적 계산을 위한 math
마지막으로 왜도와 첨도를 구하기 위한 scipy.stats 이렇게 5가지 입니다
코드)
bs = pd.DataFrame(pd.read_csv('/content/drive/MyDrive/test/bs.csv', encoding = 'cp949'))
bs1 = pd.DataFrame({'mmt' : bs['mmt']} )
bs1.index = bs['date']
r1 = np.arange(0, 588, 12)
jan2 = pd.date_range('1973-01', periods = 49, freq = '12M')
jan3 = jan2.strftime("%Y-%m").to_list()
jan = bs1.iloc[r1]
jan1= np.mean(jan['mmt'])
hjk = np.arange(1, 50, 1)
fp1 = np.polyfit(hjk, jan['mmt'] - jan1, 1)
f1 = np.poly1d(fp1)
fig, ax = plt.subplots(figsize = (15, 9))
ax.scatter(hjk, jan['mmt'] - jan1, color = 'deepskyblue', zorder = 2, s = 50)
ax.plot(hjk, f1(hjk), lw = 2, color = 'red')
ax.set_xlabel('Date(1973-01 ~ 2021-01)', fontsize = 20)
ax.set_ylabel(r'Anomaly($\ x_i - \bar{x}$)', fontsize = 20)
ax.set_title('Busan 1973 ~ 2021 January Anomaly', fontsize = 20)
ax.grid(zorder = 1)
plt.xticks(np.arange(1, 50, 1), labels = jan3, rotation = 45)
#plt.savefig("/content/drive/MyDrive/기상통계학/January anomaly.png", dpi = 300)그림 하나를 그리기 위한 코드는 이렇게 되어 있습니다
제가 아직 함수, def를 사용하는 게 익숙하지 않아서 계속 공부 중입니다
추후에 함수로 반복문을 좀 줄인다면 추가로 포스팅해보겠습니다!
분석 들어갑니다
1) 자료 불러오기
bs = pd.DataFrame(pd.read_csv('/content/drive/MyDrive/test/bs.csv', encoding = 'cp949'))
bs1 = pd.DataFrame({'mmt' : bs['mmt']} )
bs1.index = bs['date']자료 불러오는 부분은 이제 익숙 하실거라 생각합니다
pd.read_csv로 읽어오는 동시에 DataFrame 형태로 바꿔줬습니다
지점명이 한글로 되어 있다 보니까 csv를 불러오는 과정에서 utf-8 에러가 뜨기 때문에
encoding = 'cp949'로 utf-8에서 cp949 형태로 바꿔줬습니다
pandas가 친절하게 한글을 읽어주면 좋겠지만 그러지 못하기 때문에 저희가 번역을 해서 입력시켜준다 라고 생각하시면 됩니다
그리고 저희가 필요한 평균최고기온과 날짜만 가져오기 위해서
새로운 DataFrame을 만들어서 컬럼에 mmt,. 평균 최고기온을 넣어주고
date를 index로 설정해주었습니다
다음 코드에서 1월만 추출해야 하기 때문에 날짜를 index로 설정했습니다
2) 1월 자료 추출하기
r1 = np.arange(0, 588, 12)
jan2 = pd.date_range('1973-01', periods = 49, freq = '12M')
jan3 = jan2.strftime("%Y-%m").to_list()
jan = bs1.iloc[r1]
jan1= np.mean(jan['mmt'])
저희가 새로 만든 DataFrame입니다
필요한 것만 남아서 좋긴한데 월 별로 편차를 구하고 싶기 때문에 1월만, 2월만 이렇게 추출을 해야합니다
그래서 iloc라는 메소드를 사용할 겁니다
데이터 프레임에서 자료를 추출하는 방법은 두 가지 방법이 있습니다
index를 기준으로 추출하는 iloc, column을 기준으로 추출하는 loc 이렇게 2가지 입니다
저희는 index로 설정한 날짜에서 월별로 추출할 거기 때문에 iloc를 사용하겠습니다
loc와 iloc 이름을 보면 아실 수 있듯이 index location 이라는 뜻입니다
2021년 1월과 2022년 1월은 12달 차이기 때문에 총 자료 길이에서 12 간격으로 추출을 한다면? 1월만 나오겠져
그 부분은 np.arange(0, 588, 12)로 할 수 있습니다
추출된 결과를 볼까요?
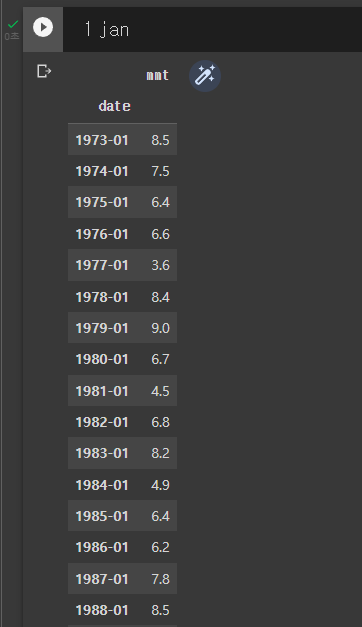
깔끔하게 1월만 출력이 된 모습입니다
편차를 구하려면 평균이 필요하기 때문에 np.mean을 통해 49년간 1월 평균최고기온들의 평균을 구해줬습니다
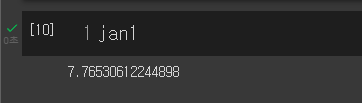
7.76 정도의 값이 나오네여
이렇게 평균까지 구해준 모습입니다
jan2 = pd.date_range('1973-01', periods = 49, freq = '12M')
jan3 = jan2.strftime("%Y-%m").to_list()이 부분은 그림을 그릴 때 x축 tick 라벨로 사용하기 위해 1973-01 부터 2021-01까지
만들어서 리스트 형태로 만들어줬습니다
3) 추세선을 그리기 위한 학습
hjk = np.arange(1, 50, 1)
fp1 = np.polyfit(hjk, jan['mmt'] - jan1, 1)
f1 = np.poly1d(fp1)저희는 49년 동안 평균최고기온이 어떤 추세를 보여주는지
증가하고 있는지 감소하고 있는지를 확인하기 위해 추세선을 그려주겠습니다
선형 회귀 분석이라고 하는 일종의 분석 방법 중에 하나입니다
scikit learn이라는 라이브러리를 사용해도 되지만 저는 np.polyfit과
np. poly1d로 새로운 방법으로 추세선을 만들어보겠습니다
선형 회귀 분석은 두 가지 변수가 있을 때 이 변수들이 선형적으로 어떤 관계인지를 분석하는 기법입니다
예를 들어 15명의 학생이 있고 영어 점수와 수학 점수가
math = [64, 75, 68, 87, 76, 70, 90, 72, 60, 70, 80, 76, 84, 81, 57]
english = [83, 80, 67, 91, 73, 92, 85, 76, 72, 81, 96, 67, 69, 87, 64]
이렇게 있다고 해봅시다
이 점수들을 x축을 수학 점수, y축을 영어 점수로 해서 산점도를 그리고
f1 = np.poly1d(np.polyfit(math, english, 1))아래 코드를 통해 추세선을 그려주면
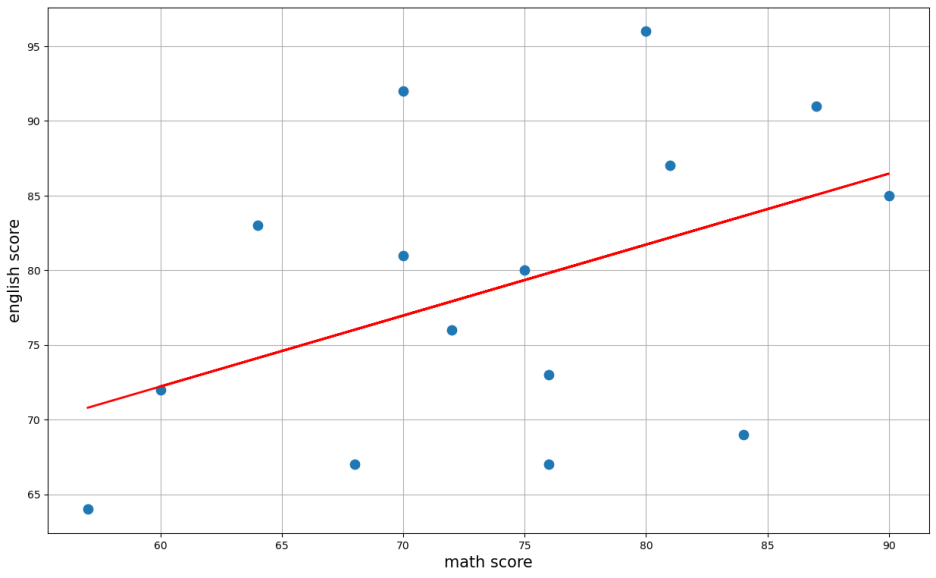
이렇게 그려지게 됩니다
이러한 경우를 양의 상관 관계가 있다고 표현합니다
그럼 반대로 기울기가 음수가 나오면? 음의 상관 관계가 나온다고 할 수 있습니다
선형 회귀 분석이나 다른 통계 분석들은 따로 포스팅에서 다루겠습니다
이렇게 저희가 그릴 평균최고기온도 값들을 훈련 시키겠습니다
하지만 날짜를 x축에 넣는 것은 불가능합니다
날짜는 년도만 꾸준히 증가할 뿐 월은 12월이 되면 다시 1월로 돌아오기 때문에 변수로 넣을 수가 없습니다
그래서 년도가 증가하는 점을 이용해서 49년이기 때문에 np.arange(1, 50, 1)을 사용해서
49개의 숫자를 뽑았습니다
그 후 이렇게 뽑은 변수와 온도를 학습시키는 겁니다
x축의 tick label은 나중에 라벨을 입히면 됩니다
x에 연속적으로 증가하는 변수, 그리고 y에 추세를 알고 싶은 온도 편차를 넣어서 학습을 시키고
뒤에 1이라는 숫자는 저희가 선형적으로 모델식의 차수를 의미합니다
1이면 1차함수, 2면 2차함수 이렇게 됩니다
poly1d는 입력시킨 값들로 식을 만들어 줍니다
이렇게 하면 추세선을 그릴 준비는 끝납니다
4) 그래프 그리기
fig, ax = plt.subplots(figsize = (15, 9))
ax.scatter(hjk, jan['mmt'] - jan1, color = 'deepskyblue', zorder = 2, s = 50)
ax.plot(hjk, f1(hjk), lw = 2, color = 'red')
ax.set_xlabel('Date(1973-01 ~ 2021-01)', fontsize = 20)
ax.set_ylabel(r'Anomaly($\ x_i - \bar{x}$)', fontsize = 20)
ax.set_title('Busan 1973 ~ 2021 January Anomaly', fontsize = 20)
ax.grid(zorder = 1)
plt.xticks(np.arange(1, 50, 1), labels = jan3, rotation = 45)이제 그림을 그리는 부분입니다
fig, ax로 도화지와 그림을 만들어주고
scatter plot으로 편차들을 그려줍니다
추세선은 line plot으로 x축에 1부터 49까지의 수, y축에 앞에서 만들었던 함수식에 x값을 넣어주는
저희가 쉽게 알 수 있는 일차함수를 계산하는 것과 똑같습니다
그 후 x축, y축의 label을 달아주고 tick 라벨을 달아주면
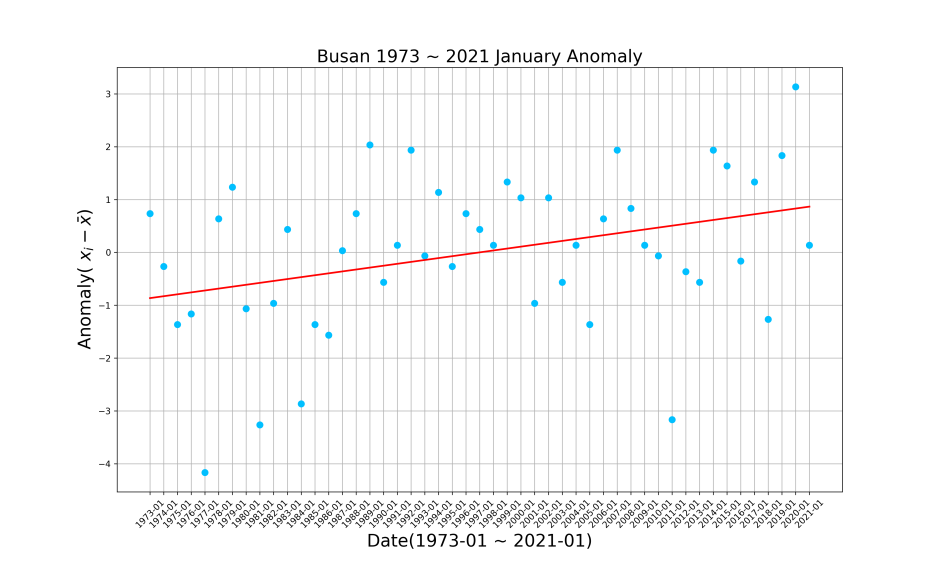
이렇게 예쁜 그림이 나옵니다
그러면 평균 최고 기온의 편차는 상승 상승하는 추세를 보인다 라는 걸 알 수 있습니다
평균은 고정이지만 관측 값에서 평균을 뺀 편차가 상승한다는 것은 관측 값이 상승하는 추세를 보인다는 것도 생각해 볼 수 있습니다
또 그래프의 기울기를 봤을 때 상승 추세가 많이 가파르지는 않은 걸 알 수 있습니다
기울기를 직접 구해보면

1에 가까울 수록 상관 관계가 강하다고 할 수 있지만 0.348 정도로 훨씬 작은 값이 나오는 걸 알 수 있습니다
이걸로 보아 1월 달의 평균 최고기온은 상승하는 추세는 보이나 강한 상승 추세는 아니다 라는 결과를 도출할 수 있습니다
생각보다 포스팅이 길어져서 표준편차는 다음 포스팅에서 다뤄보겠습니다
'파이썬' 카테고리의 다른 글
| 작업12: Python으로 부산 평균 최고기온 분석하기3 (0) | 2022.11.05 |
|---|---|
| 작업11: Python으로 부산 평균 최고기온 분석하기 2 (0) | 2022.11.05 |
| 작업9 : Python으로 파장별 복사에너지 그래프 그리기 (0) | 2022.10.26 |
| 작업8 : Fortran으로 만든 자료 시각화 (0) | 2022.10.26 |
| 작업7 : Python을 통한 GUI 프로그래밍2 (0) | 2022.10.18 |